
Дата публикации:Thu, 22 Jun 2023 12:41:43 +0300
Компании Intel и Blockade Labs совместно разработали модель машинного обучения LDM3D (Latent Diffusion Model for 3D) для генерации изображений и связанных с ними карт глубины на основе текстового описания на естественном языке. Разработка напоминает систему синтеза изображений Stable Diffusion, но позволяет формировать трёхмерный визуальный контент, такой как сферические панорамные изображения, которые можно просматривать в режиме 360 градусов. С практической стороны модель может применяться в играх и системах виртуальной реальности для интерактивного формирования трёхмерных окружений.
Для свободной загрузки предложена готовая модель для систем машинного обучения, которую можно использовать с PyTorch и кодом, рассчитанным на генерацию изображений при помощи моделей от проекта Stable Diffusion. Модель распространяется под пермиссивной лицензией Creative ML OpenRAIL-M, допускающей использование в коммерческих целях. Распространение под открытой лицензией даёт возможность исследователям и заинтересованным разработчикам улучшать модель в зависимости от своих потребностей и оптимизировать её для узкоспециализированных применений.
Для обучения модели использован открытый набор данных LAION-400M, подготовленный сообществом LAION (Large-scale Artificial Intelligence Open Network), развивающим инструменты, модели и коллекции данных для создания свободных систем машинного обучения. Коллекция LAION-400M включает 400 миллионов изображений с текстовыми описаниями.
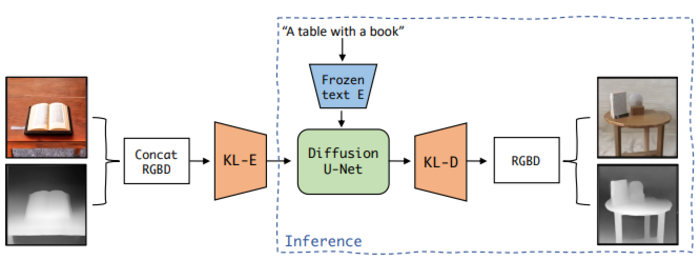
Помимо изображений и их текстовых описаний при обучении модели LDM3D также задействованы карты глубины, сгенерированные для каждого изображения при помощи системы машинного обучения DPT (Dense Prediction Transformer), позволяющей прогнозировать относительную глубину каждого пикселя плоского изображения. По сравнению с технологиями прогнозирования глубины на стадии постобработки, модель LDM3D, изначально обученная с учётом глубины, позволяет получать более точную информацию о глубине на стадии генерации. Другим достоинством модели является возможность выдачи данных о глубине без увеличения числа параметров - число параметров в модели LDM3D примерно соответствует последней модели Stable Diffusion.

Для демонстрации возможности модели подготовлено приложение DepthFusion, позволяющее на основе двумерных RGB-изображений и карт глубины создавать интерактивные окружения для просмотра в режиме 360-градусов. Приложение написано на визуальном языке программирования TouchDesigner, подходящем для создания интерактивного мультимедийного контента в режиме реального времени. Модель LDM3D также может использоваться для генерации и изменения изображений на основе предложенного шаблона, проецирования результата на сферу для создания окружающего пространства, генерации изображений с учётом различных позиций наблюдателя и формирования видео на основе виртуального перемещения камеры.
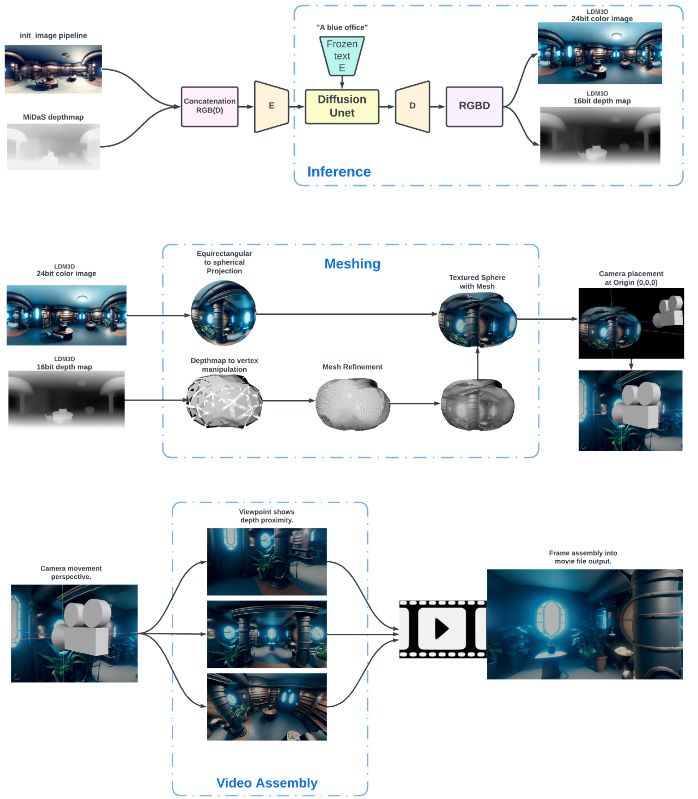
Предполагается, что предложенная технология обладает большим потенциалом в создании новых методов взаимодействия с пользователем, которые могут оказаться востребованными в различных индустриях - от развлечений и игр до архитектуры и дизайна. Например, LDM3D может применяться для создания интерактивных музеев и окружений виртуальной реальности, формирующих детализированное окружение на основе пожеланий на естественном языке.
Новость позаимствована с opennet.ru
Ссылка на оригинал: https://www.opennet.ru/opennews/art.shtml?num=59325